
DITA文件翻译的痛点
DITA翻译的核心原理是通过分离内容和格式,将源文档转化为可重用的组件,并通过翻译记忆库(Translation Memory)来提高翻译效率。然而,相较于传统文件的翻译,DITA文件因其应用的特殊性,会产生很多额外的问题:
- 内容碎片化:由于DITA重用的特点,DITA文件的内容组织可能分散到多个文件和模块中。一方面,这可能导致翻译时上下文的丢失和不连贯性,另一方面,当翻译项目包含的DITA文件过多时,译员需要在不同的文件之间跳转。
- 引用处理困难:DITA中的引用机制(如conref和keyref)使得处理引用内容的翻译变得复杂。如果技术写作项目包含大量引用(包括项目文件夹之外的引用),那么写作人员或译员需要面临一些棘手的译后处理问题。例如:如何提取需要翻译的文件、如何在翻译完成后生成新的小语种文件夹、如何保证目标文件中引用关系依然正确等。在传统翻译工作流中,这几项任务通常需要手动完成。
- 源文件更新繁琐:理想条件下,翻译应该在源文件定稿后进行。但受限于实际资料开发进度以及评审滞后等因素,往往在送翻之后,原文会有规模不等的更新。常见的解决办法包括:手动提取变更的内容汇总到表格中,重新送翻;或者,将变更的文件单独提取出来送翻。无论是哪一种,都会消耗额外的人力或翻译费用。
Introducing Fluenta
什么是Fluenta
Fluenta是一款旨在简化DITA项目翻译的开源工具。通过结合OASIS的两个开放标准DITA和XLIFF,它旨在简化DITA项目的翻译和本地化工作。Fluenta能够与翻译记忆库(TM)进行无缝集成,利用先前翻译过的文本来提高翻译效率和一致性。它可以自动匹配和应用翻译记忆库中的翻译段落,减少重复工作并确保术语和翻译的一致性。通过解析DITAMAP和DITA文件,Fluenta可以生成一个统一的XLIFF文件。
与常见的CAT工具不同,Fluenta专为DITA设计。官网介绍了Fluenta的特点,包括:
- 能够解决DITA内容引用,例如
conref属性或keyref机制。 - 支持允许自定义可翻译元素和属性的DITA专业化。
- 理解translate属性。例如,当设置
@translate=no时,该内容元素将不会被Fluenta提取。
为什么是XLIFF文件
XLIFF(XML Localization Interchange File Format)是一种XML格式,旨在促进软件和内容的本地化和翻译过程的交换和共享。它是一种开放、标准化的文件格式,由OASIS组织开发和维护(与DITA类似)。理论上,所有的CAT工具都支持翻译XLIFF文件,因此XLIFF文件可以在不同的本地化工具和环境中使用和共享。此外,XLIFF的主要特点为:
- 结构化:XLIFF文件采用基于XML的结构,可以按照预定义的元素和属性进行组织和描述。这使得XLIFF文件易于解析和处理,并且具有良好的可扩展性。
- 分割和标记:XLIFF文件将源文本分割为可翻译的单元,例如段落、句子或标签。每个翻译单元都包含源文本和与之对应的目标语言文本。 "
| |
借助XLIFF文件,辅助翻译工具可以进一步存储翻译记忆、执行版本控制以跟踪翻译的不同阶段等。
安装与使用Fluenta
方法一:通过GitHub下载桌面应用
目前Fluenta分发开源版本和订阅版本(200美元/年)。如需使用开源版本,还需要进行一定的配置。
开发环境:
- Java 17 +
- Apache Ant 1.10.12 +
安装流程:
- 确认Java和Ant的环境变量设置正确。
- JAVA_HOME:指向JDK安装路径
- ANT_HOME:指向Ant安装路径
- 访问Fluenta的GitHub Repo:https://maxprograms.com/products/fluenta.html
- Fork-Checkout Repo或下载压缩文件到本地。
- 设置
JAVA_HOME的系统变量,使其指向JDK 17的安装路径。 - 从
SWT文件夹复制对应版本的swt.jar到jars文件夹。 - 在Fluenta的安装路径中打开命令行工具,运行
ant编译。 - 编译完成后,根据系统运行对应的批处理文件即可使用。
- Windows:
fluenta.bat - MacOS:
fluenta_mac.sh - Linux:
fluenta_linux.sh
- Windows:
方法二:通过Oxygen XML Editor安装插件
自v25.0起,Oxygen XML editor 支持以插件的形式安装Fluenta并管理基于Fluenta的翻译工作流。
安装流程:
- 选择 Help > Install new add-ons 打开插件对话框。
- Show add-ons from 选择 https://www.oxygenxml.com/InstData/Addons/default/updateSite.xml。
- 选择Fluenta Dita Translation, 点击Next。
- 勾选同意用户协议,点击Finish。
- 重启Oxygen,使变更生效。
实践经验分享
由于我使用方法一安装的Fluenta无法正常使用,因此下文以Oxygen+Fluenta插件的实际使用经历为例,分享具体的翻译工作流程。
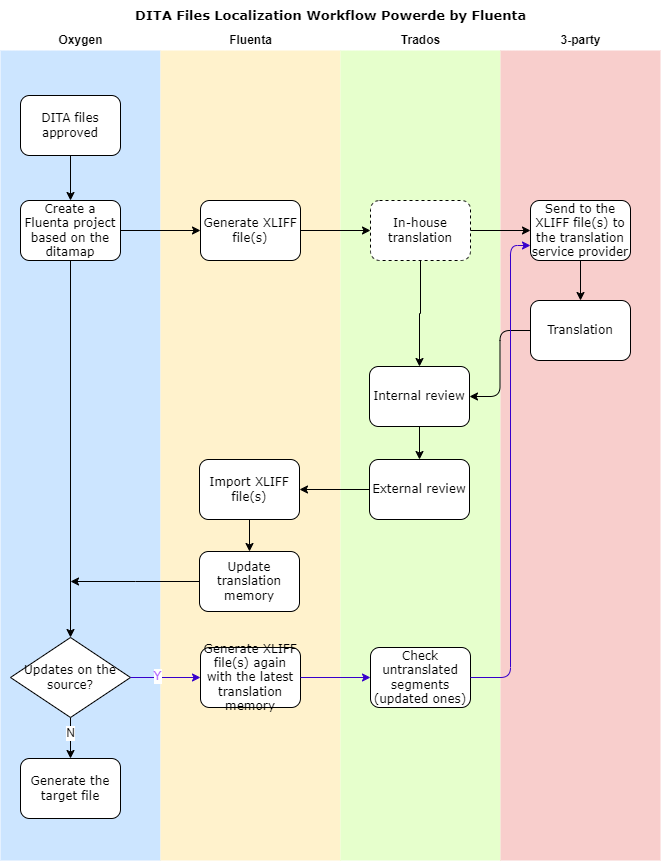
创建Fluenta项目。
以DITA Map Manager视图打开.ditamap文件。
选择该DITAMAP,右键选择Fluenta > Create Project,打开创建Fluenta项目对话框。
在弹出的对话框中,输入项目名称,选择源语言并添加目标语言。
注意: 可选择多个目标语言。
点击Create project,创建项目。
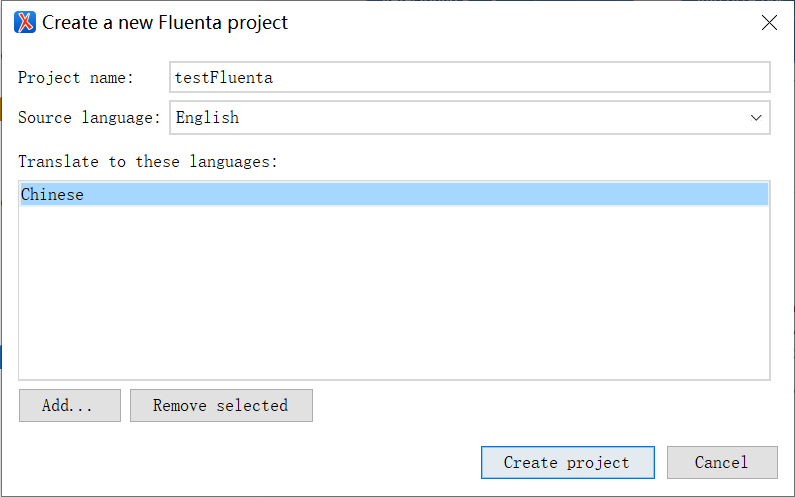
生成XLIFF文件。
以DITA Map Manager视图打开.ditamap文件。
选择该DITAMAP,右键选择Fluenta > Generate XLIFF。
在弹出的对话框中,选择XLIFF文件的存储路径。
勾选目标语言,点击Generate。
注:建议保持其他设置不变。
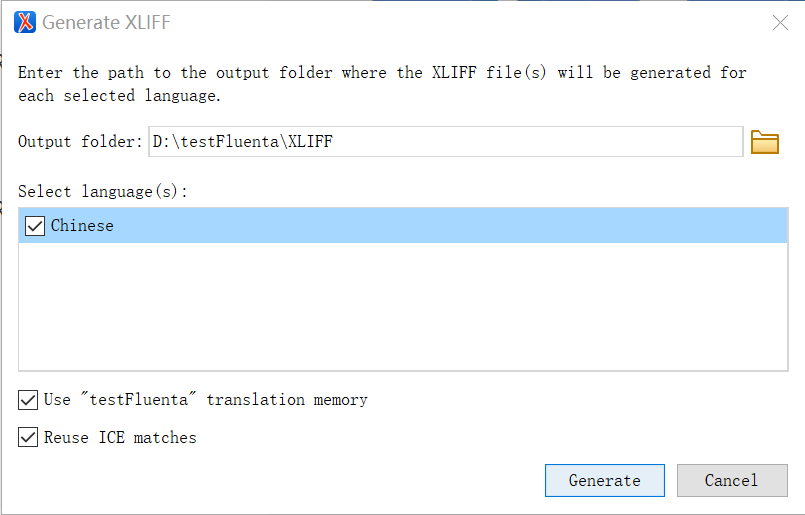
翻译。
- 如果由内部翻译,直接利用CAT工具打开生成的XLIFF文件开始翻译。
- 如果由外部翻译,将生成的XLIFF文件单独或以项目包的形式发送给翻译服务供应商。
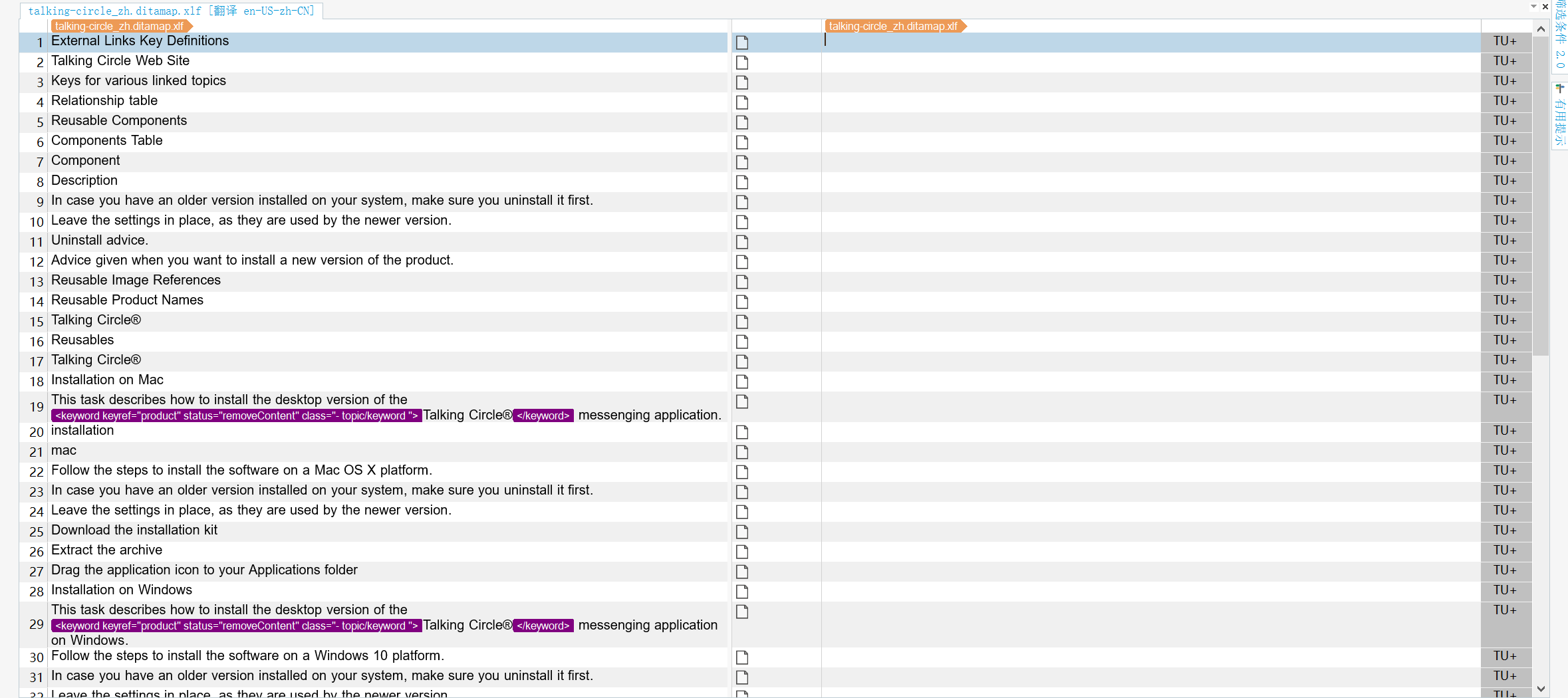
审阅。
- 利用CAT工具或LQA工具对译文进行审阅,确保没有漏译、错译等问题。
- 确认的译文可更新相应句段状态为”已翻译“。
导入翻译好的XLIFF文件。
以DITA Map Manager视图打开.ditamap文件。
选择该DITAMAP,右键选择Fluenta > Import XLIFF。
在弹出的对话框中,选择翻译好的XLIFF文件。Fluenta会自动根据当前项目文件夹的构成,自动生成目标语种文件夹的对应路径。
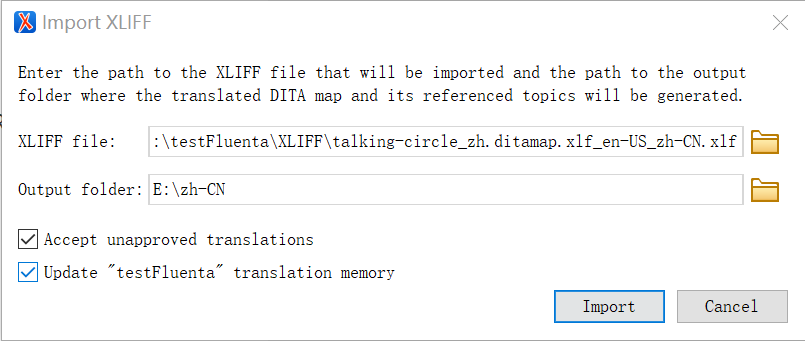
点击Import,导入译文。
生成输出。
- 在Oxygen中打开目标语种的项目文件夹,选择对应的.ditamap生成输出。
优势
- 提高翻译效率:基于Fluenta的翻译工作流程使得翻译DITA文件更简单和流畅,而Oxygen中内置Fluenta也减少了译后文件管理的繁琐工作,能有效提高翻译效率。写作人员还可以设置好内容元素的翻译属性,让译员仅翻译“需要翻译”的内容。相应地,写作人员也可以设置选择导入状态为“已翻译”的内容。
- 保证翻译质量:Fluenta集成了翻译记忆库,支持以项目(DITAMAP)为单位自动创建、更新翻译记忆。借助其他CAT工具可以有效避免“重复翻译”的问题,节省了时间和人力资源。
- 格式标准,使用灵活:XLIFF格式适用于市面上的多种CAT工具,无需担心译员无法打开文件的问题;也可以转化为Word格式,方便不使用CAT工具的译员使用或进行外部审校;由于XLIFF文件是基于XML的文件格式,因此也支持识别SVG格式图片中的文本;此外,导入目标XLIFF文件之前,Fluenta会进行简单的质检,如确认标记对应正确。
劣势
- 导入XLIFF文件后,发现仍有极个别的内容元素没有更新,无法完整导入译文。(待确认是否是工具Bug。)
- 在多语种DITA文件管理方面,导入只会在主map平级目录下新增小语种文件夹。如果有外部引用,译文会完整替换外部的DITA文件。
- 源DITA文件包括大量重用内容,而生成的XLIFF文件未将原内容和重用的内容视为同一内容,导致翻译内容增多,翻译成本相应提高。(待进一步判断是工具Bug还是设置问题。)
使用建议
在“Using XLIFF to Translate DITA Projects”一文中提到了仔细规划DITA内容的重要性,以及降低成本的相对性。
DITA 承诺通过内容重用降低翻译成本。如果进行适当的规划,内容重用可以降低翻译成本。Topic编写一次,更新一次,并在多个可交付成果中使用。通过仔细规划,成本确实可以降低。然而,成本降低取决于项目的性质;不可能提前预测成本削减的程度。
根据实际实践感受,目前可以总结一些使用Fluenta的使用建议:
- 提前准备:确保DITA文件内容组织合理,且没有项目文件夹之外的内容引用。
- 标记非译内容元素:如果该标记对内的内容不需要翻译,设置@translate=no。
- 校验文件质量和风格:确保DITA项目文件已进行简单的完整性检查和风格校验。
- 核对XLIFF文件:第三方翻译完成后,将XLIFF文件导入Trados或其他CAT工具,进行简单的LQA检查(如标记对使用正确、所有译文均翻译等)。仅校对后的XLIFF文件才可以导入生成目标翻译。
- 累积翻译资源:Fluenta支持将导入的XLIFF文件转换为TMX格式。翻译项目完结后,可根据需求将翻译新增的内容更新到相应的翻译记忆库中。
参考资料
- Fluenta DITA Translation Add-on
- Fluenta DITA Translation Manager
- Using XLIFF to Translate DITA Projects——An OASIS DITA Adoption Technical Committee Publication
Featured image fron Unsplush